

Scientific meme content
Scientific meme content
Of amateurs, poison-for-profit, and the manipulation of public opinion


Background:
The origins of SARS-CoV-2 remain a controversial and hotly debated topic among the public, often to the frustration of many domain experts. While not all mysteries are yet solved, and perfect knowledge is unrealistic, what can be said is that the laboratory accident (‘lableak’) theory is dead in the water, failing to accumulate any evidence supporting it in the scientific literature for almost three years. If you have not been deeply engaged with this topic, this dry assessment might be surprising to you. You might even come across some of the continued sensationalist claims about a ‘possible’ lableak from many influencers, social media, and even news outlets. Where does this discrepancy between science and society come from?
Well, for one, it comes from our broken information sphere. As I have written previously, the lableak theory might be dead, but the lableak conspiracy myth is alive and well, especially on social platforms and in the heads of people. Conspiracy myths profit from asymmetric forces that shape our broken info sphere, because they garner a lot of attention. Boring, factual, and nuanced scientific or expert assessments can not compete in this information environment, they do not reach broad audiences, that’s why you might not even have heard about the emerging scientific consensus for a zoonotic origin. That’s also why you are most likely not aware of the body of detailed geographical, genomic, historical, statistical, epidemiological, and phylogenetic evidence scientists have accumulated until today to judge and discard alternative hypotheses, including lableak (feel free to check references & further reading below).
But a broken info sphere is only one part of the equation. There is a more insidious underbelly to the problem, and it has everything to do with humans, not technology. It also extends far beyond the origins controversy. We are currently in an epistemic crisis, where large parts of society lost the ability to assess what is real or true online on a range of topics, and this creates a vulnerability for democracy that malicious actors can exploit. These actors go by many names and functions; disinformation peddlers, grifters, contrarians, quacks, influencers, outrage entrepreneurs, information combatants, or merchants of doubt. But what unites them is that they share one common enemy: Science.
Science does not operate at attention economy speed, nor should it. That makes it an easy target.
Science has the inherent authority to create, assert, dispute, and correct information, it is the ultimate arbiter of solving informational conflicts or contradictions, thus creating a larger shared reality to seek cooperation and progress in, together. Science also provides the necessary cool against the heat of public discussion, the pace of day-to-day commentary, and our hot-headed human immaturity that resurfaced with the new information systems of our age.
For all these reasons, science is a threat to the ‘alternative’ information peddlers, to influencers and businesses and politicians, to all forces who dominate in the current world of fragmented realities. The winners of the attention economy seek to entrench their current power over separate little epistemic fiefdoms, both online and offline. But where the light of science retreats from the public, the shadow of manipulation looms ever larger.
How this manipulation plays out surrounding the lableak controversy is a convenient topic for me to write about, because it somewhat falls into my professional expertise and interest. Yet it is merely a sideshow. I could also talk about anti-vaccine conspiracy myths, discourses of climate delay, or any other topic where society and science are driven apart. In a democracy, I believe nobody deserves to be bombarded with lies and manipulated in their beliefs on any scientific topic just because they lack the time, passion, or expertise to deeply engage in a technical discussion that has little relevance to them.
We all deserve an unpoisoned info sphere to form our opinions, but that interferes with the strategic aims of influencers & malicious actors.
Using recent examples from the lableak conspiracy myth as a case study, this article will shine a light on the tactics of (what I call ‘poison-for-profit’) anti-science forces and mechanisms. This article will also equip the average reader with tools to spot bad science and hopefully provide some much-needed clarity about trust in ‘mainstream’ science. It’s ambitious but necessary. So let’s get started.
Chapter 1: An alternative reality ecosystem
The fight for information supremacy
First and foremost: Scientists are no strangers to pushback and dissent on their work, in fact, science is set up to allow other scientists and interested parties to advance contradictory arguments with new data, criticize or analyze available data and offer new perspectives. It is a very egalitarian culture in the sense that any hypothesis (usually in form of a scientific paper) will be judged on its merits, no matter who brings it forth. This only works because the scientific system is (among other things) reputation based, where updating one’s belief with the evidence is seen as reputable, and sticking to one’s opinion despite the facts is treated with scorn. No system made by humans is perfect, and neither is science. Many have written about the pros and cons of this system, or how ‘publish-or-perish’ comes with bad incentives that can be gamed as well. But what I want to focus on here is something most people, including scientists, have not yet wrapped their heads around. Meme papers.
What are scientists supposed to do when scientific papers are not written for advancing knowledge, but solely for public effect?
Welcome to scientific meme content
In the information age, it is useful to conceptualize information as a product, and influencers as information merchants. Most information merchants online create elaborate information products that have a unique appeal and are custom-made for a specific audience of the attention market.
If there is an audience demand for ‘alternative facts’ of why “vaccines are very dangerous”, why “Putin is actually the good guy” or why “climate change is just a hoax”, influencers will deliver content for it, be it in the form of op-eds, twitter-threads, memes, blog posts or sometimes preprints articles and published papers. The last two is what I call ‘scientific meme content’.
‘scientific meme content’, information products that are created to look like authentic scientific work to further an idea in public, including technical language and figures and arguments, sometimes even deliberate fraud, but without offering either original data, relevant results, or scientific value
Scientific meme content is a relatively new installation of the information economy, but as with many things, it is the continuation of already existing practices. Information merchants have always tried to abuse science or scientific language for personal gain, way before the internet. Quack doctors, ‘natural health’ influencers, pseudoscience peddlers, scaremongering journalists, political ideologues, and unethical corporations all profit from producing or abusing shoddy science and flaky statistics, this is not new. (Also, read: Ben Goldacre’s Bad Science, an excellent book on the topic).
What is also new is that in the attention economy, influencers (and their parasocially motivated followers) contribute and worsen the problem significantly through a dangerous mix of scientific incompetence, attention economy incentives, and asymmetric amplification mechanisms.
This combination is what breaks the Camel’s back for scientists.
Just a small note: Throughout the article, we will be collecting what I call ‘trust lemmata’, basically small nuggets of insight that will help us later to figure out what makes a scientific source more or less trustworthy. You might also think of them as proverbial ‘red flags’ for discerning untrustworthy sources.
Section A) (Social) Media-empowered amateurs and contrarians
Fair warning: The next two sections will get a bit technical. So if you are not here for the scientific takedown of meme content, you can jump right to section C. For everybody else, I will try to make it somewhat readable for non-experts & outsourcing further details to references.
Everybody has their favorite enemy.
When it comes to the lableak controversy, one of the biggest rallying cries of contrarian ‘scientists’, motivated amateurs, and conspiracy myth truthers have been two recent scientific studies on the origins of SC2 in the journal ‘Science’, namely Worobey M. et al., Science, 2022 and Pekar J. et al., Science, 2022.
Simplified: These two studies provide a large body of detailed evidence that established the Huanan Seafood market as the place of origin of the pandemic, most likely via multiple zoonotic spillovers from wildlife sold there, seeding the first two human lineages somewhen around late November.
Because of these findings, many actors with various motivations have a high interest in attacking the results, validity, or researchers of these studies. (Worth mentioning again that scientists welcome scientific challenges to their work. The problem arises when those challenges are directed to manipulate the public, often without making a coherent scientific case)
Let’s get started:
Case example 1: One preprint by Massey et al., set out to challenge Pekar et al., based on a thinly veiled insinuation that the latter inappropriately excluded data of supposedly ‘transitional genomes’ to push a two spillover scenario. (The lack of transitional genomes between lineage A and B is one, but by far not the only indication that two lineages spilled over separately into humans from animal hosts. Multiple spillovers are common and expected for zoonotic viruses, but a strong argument against any lableak).
Massey et al. further falsely allege that Pekar et al., committed multiple basic errors and their work is plagued with inconsistencies. The only evidence they offer for their dramatic claims of basically research fraud are downloads of publicly available raw data (SRE files containing sequencing reads) of contested ‘transitional genomes’ when available and map them to (lineage-defining) mutational positions 8782 and 28144. They then blot and count the reads at these positions to basically assert ‘looks transitional to me’ and thereby state the vast majority of transitional genomes are actually real and should not have been excluded.
To understand the fuss, here is the baseline science:
For their phylogenetic analysis, Pekar et al. found characteristic mutations in these supposed ‘transistional genomes’ that made them wary about the ‘realness’ of them. Phylogentics is tree building, and when transitional genomes that are supposed to be sitting at the trunk of the tree suddenly share the same twigs (mutations) as the crown of the tree, extra scrutiny was required. So the bioinformatic experts set out to check if there were obvious problems with these genomes, and to their surprise, none of the 20 supposed ‘transitional genomes’ held up. About half of the (falsely called) lineage-defining mutations in those genomes came about from a known software artifact (where the software fills in the reference genome position if it can not determine the base call), others were plagued with contaminations or low read coverage at the position of interest. Removing these untrustworthy genomes is standard operating procedure and good scientific practice.
Now explaining all the details of where Massey et al., went wrong to claim these were ‘real’ transitional genomes would require a lot more technical education about sequencing pipelines, PCR artifacts, stochasticity, etc, so maybe let’s just focus on two very obvious mistakes:
First, read depths. Read depths is a measure of how many sequencing reads (usually between 75–150 nucleotide-long stretches) cover a given position in the genome, the more reads for each position, the stronger the evidence of what that actual position looks like. Sequencing read quality varies widely, they have sequencing spacers (also nucleotides) on the side to be amplified in PCR reactions, and if your PCR amplifies trillions of these pieces, many of them will have either mixed with other sequences, dimerized, be partially amplified, reannealed etc.. basically creating a weird variety of sequences, or better said: unrepresentative noise. This is of course not the only way how false reads can come into a sample, another prominent one is contamination during RNA extraction. In any case, noise is only a problem when the signal is weak. If at any genomic position, 1000 reads cover it, having 2 or 5 or 10 ‘weird’ noisy sequences there as well does not reduce our base-calling confidence much. But because of their stochastic nature, having a position covered with only 5 reads could really mess up your signal. Now every bioinformatician and most molecular biologists know this, and on average, a lower threshold of at least 10x (10 reads per position) is required to have some confidence in the base calls of the position. Phylogenetics is extra sensitive to falsely-called mutations, so one just has to be stringent when filtering.

What some amateurs however do not know (or pretend to be ignorant of) is that read depths is not evenly spread throughout the genome.
Enter Massey et al., who claim that because genome-wide read depths are high for some ‘transitional genomes’, they should not have been excluded. This is nonsense, as we now understand, one has to look at read coverage of the individual position. Massey et al. are also advancing the idea that one should be less stringent with filters by using 5x coverage, and that the (well-known and common 10x threshold) is arbitrarily strict, which is, of course, motivated nonsense too (details explained by the expert thread).
I think it is save to say that we found our first red flag for scientific credibility:
Lemma I: Amateurs make amateur mistakes
The second big issue with Massey et al. are misrepresentations of the work they criticized. Pekar et. al. listed several exclusion criteria, contamination, sequencing depths, artifacts, convergence, and communication (collaborators). For each of these, the authors looked through all genomes and many were not only failing one exclusion criterion, but 2 or even 3 at the same time. This means that there were multiple scientific reasons to exclude them.
Massey et al. misleadingly highlight that some genomes that were ‘fine on read depths’ were excluded by Pekar et al, implying research misconduct. But Pekar et al. excluded these genomes in question based on other exclusion criteria, not read depths. (Namely, they were removed because of contamination and communication with collaborators, who already noticed something went wrong with these genomes). These kinds of scientific misrepresentations, when deliberate (hard to prove), are fraudulent and unethical, but in any case, self-defeating because they offer no real argument in the first place.
Criticizing researchers based on strawmen arguments is for entertainment, not science.
But more on that a bit later. For our purposes, we have a better understanding of why Massey et al. amateurish preprint insinuating research misconduct by professionals should be considered scientific meme content.
Let’s look at a new preprint, this time from a more credible scientist coming after Worobey at al., not mincing words either.
Case example 2: A preprint by Lisewski (single author) claims that Worobey et al. ’s geospatial analysis is “incomplete and biased”, furthermore, that he has divined a “more comprehensive, unbiased yet elementary statistical significance analysis of Worobey’s data”. Because of these sensationalist claims in the abstract, Lisewski’s preprint has been making the rounds online, shared by lableak advocates as yet another ‘proof’ that Worobey et al.’s (excellent btw) work has fundamental flaws. This is from the outset kind of surprising, given that Lisewski’s point of contention is just a very minor detail and has no bearing on the many lines of evidence presented by Worobey et al.. But okay.
One would assume that such strong claims from Lisewski will be well supported with data, yet all the author offers is a ‘re-sampling analysis’ of early cases in Wuhan and some unsubstantiated complaints about using median versus mean distances (median distances are less susceptible to outliers, that’s why Worobey et al. use them in there geospatial analysis to map case clusters). The biggest criticism from Lisewki is that sampling of cases produces a ‘right-skewed’ p-value distribution, basically alleging bias in Worobey’s analysis as the only reason why they find a significant association of cases to the Huanan market. Could it be true? Well, scientists are of course open to scientific criticism and welcome people engaging with their work. So Worobey et al. double-checked where Lisewski comes from. Here are some snippets of their response:
We welcome the technical comment by Lisewski, which re-analyzes a subset of the spatial distribution of COVID-19 cases […]
Lisewski kindly provided us with a copy of the code he used to conduct his analyses. Upon increasing the number of iterations to 1000 using his exact approach, the right skew in the p-value distribution disappeared. […]
Lisewski’s claims that our results were biased turn out to reflect Monte
Carlo error based on the inappropriately low sample size number he chose, which was one-tenth of what we used and reported. […]However, the additional analyses he spurred us to run indicate that the p-value of 0.017 we reported for this particular analysis of lineage B sequences was slightly conservative and that n=10,000 iterations reveals that p < ~0.015. — Worobey et al. (technical communication)
If this sounds very complicated, it really is not. Here is the visual:

So instead of disproving Worobey et al, re-analysis confirmed and improved the significance of Worobey’s result slightly. This is not uncommon of course, but certainly a head-scratcher given the bombastic claims of bias and errors by Lisewski.
Amateurs make amateur mistakes. But Lisewski is not an amateur, he has been working in his career with Monte-Carlo simulations in various projects. How come his technical comment on Worobey et al. fell short so easily? The short answer is: A mixture of motivated reasoning, overconfidence, and narcissism. That scientists like Lisewski critically engage with other studies is laudable, yet performing a very simple analysis and then claiming it did not only disprove a small facette of a big, thoroughly vetted, multi-author paper, but actually fundamentally turns its key message on its head is usually a big red flag:
Lemma II: Sensationalist claims based on flawed or trivial analyses
By now, the casual reader might be excused to think that this scientific meme-content is basically well-meaning but incompetent opinions by amateurs or over-eager contrarians or academic eccentrics who want to contribute to a scientific discussion.
However, sensationalist claims that contradict expert opinions, proclamations of trivial errors or solutions, using titles that sound like headlines rather than science, and adding ‘press statements’ and ‘lay summaries’ to preprints are all marks of scientific meme content that lends itself to circumvent scientific peer-review and directly go to the public. In fact, that is often the implicit purpose.
But it does not stop here. Incompetence can be strategic, sensationalist claims purposeful and scientific meme content a tool of war.
Section B) Unethical conduct & gaming the system
Scientific meme content is not as innocent as it looks
The information age has seen an array of preprints uploaded by motivated amateurs, cranks, and other actors, and most of those preprints remain eternally so, never making it past a scientific editor, into peer review to final publication.
However, it is not difficult to get scientifically meme content through the cracks of peer review when trying long enough
Peer review is at best a very porous filter (any filter is better than no filter) for bad science in times of predatory journals, endless paper floods and people willing to eschew and abuse the trusting institution of science.
Peer review is also incredibly easy to game by motivated actors, which brings us to:
Case example 3: Rahalkar et al., claiming they have found important clues on the origins of SC2 that Chinese scientists have been trying to hide.
To understand this, one has to move a bit into conspiracy land.
For a long time, a virus called RaTG13 has been a point of speculation and attack for motivated actors. This virus was sampled by the WIV on one of their expeditions to bat caves in 2013, to a mine that has seen mysterious pneumonia cases. When I say sampled we are talking about bat poop droplets that the researchers collected by the thousands to look for viral traces left in them. The researchers took the poop collections to their lab, use an extraction protocol to harvest viral RNA, and sequenced it for cataloging what kinds of viruses were in circulation (big difference between RNA extraction for sequencing versus trying to isolate live virus out of poop). Not every poop sample contained viral remnants, but a few did. The sequencing showed that RaTG13 (previously named CoV4991 for poop sample number 4991) was a rather unremarkable virus in 2013, because it was genetically to distant of SARS-1 related viruses, which the researchers had most interest in. In any case, long story short, once SC2 caused the pandemic, WIV looked through their database of bat sequences and found that RaTG13 had the highest sequence similarity to SC2 and announced it to the world, and ever since, some conspiracy theorists assume that the WIV had collected SARS-CoV-2 in 2013 and been hiding it ever since (others suggested RaTG13 was a template they used to engineer or serial passage SC2 from, which is also amateurish nonsense given what we know about genomic mosaicism and recombination of CoVs, but I digress).
Point is, in this background, motivated conspiracy theorists set out ‘re-investigate’ the pneumonia cases (fungal infections) from 2013 in order to boost their narrative that the WIV is covering up that they had SC2 all those years.
The only problem: Rahalkar et al., a married couple, have no experience in medicine, and no data but an old master thesis of a WIV student they google translated. But what they do have is some friends to help them get their meme content published (see figure below).
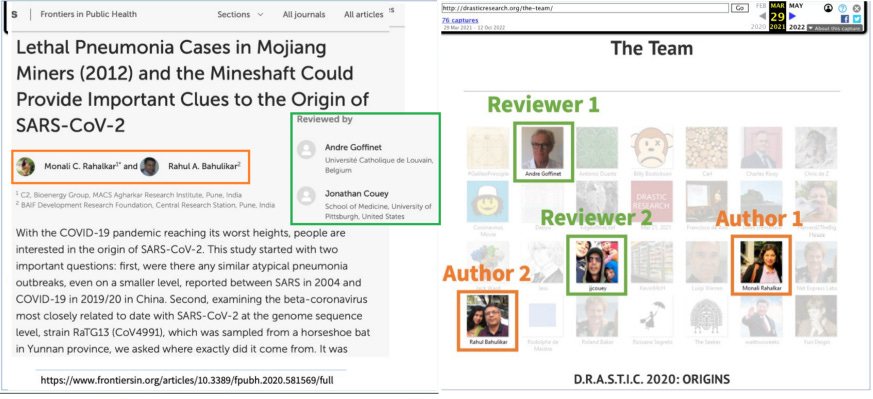
Peer review is supposed to be blinded and independent, and gaming it that way (and coordinating throughout) is considered unethical by scientists. I guess this brings us to another read flag:
Lemma III: Unqualified authors, reviewers, and/or unethical conduct.
This behavior is of course a common theme among the lableak ‘community’. All meme content that furthers the conspiracy myth is welcome, no matter how naive, flawed, amateurish, or riddled with conflicts of interest. This is why there is so much bad science coming from this community in the first place:
Another commonality is no correction, no internal criticism, and no loss of reputation for being wrong repeatedly or having a history of more embarrassingly conspiratorial content
— Dr. Zach Hensel, who has been doing unpaid work to refute and debunk nonsensical & fraudulent lableak meme content
The modus operandi is simple: If you are wrong, don’t reflect, just give it another go with a different made-up theory. Eventually, you might get lucky or trick reviewers to get published. It’s a numbers game.
Once meme content made it through peer review, it profits from the credibility boost a scientific journal bestows upon accepted work
Now while scientists are well aware that different journals have different qualities and credibility, and that peer review is not difficult to game, the public is mostly unaware of these dynamics and histories. For most of us, it is a wash, the same way many do not understand why a ‘Doctor’ pushing homeopathy is no more credible than a mechanic when doing so.
Let me just give some sidenote here: In general, individual studies do not hold a lot of power in science, they are like puzzle pieces that scientists accumulate to gain an ever more comprehensive picture of the larger whole, our shared reality. The value of any puzzle piece is not only just a feature of it’s individual scientific strength or merit but how well it fits with that larger picture. Having a study showing that glaciers have been melting in the Alps might indicate that climate change is really happening, but the true power of science comes from hundreds of studies showing that ocean temperatures, satellite imaging, physical models, temperature measurements all around the world etc… are consistent with the bigger picture ‘climate change is happening’.
Meme content that passes peer review is similar to random puzzle pieces that can never connect to any bigger picture, they annoy scientists because it just adds useless pieces (noise) to an already very large, incomplete and difficult puzzle.
Eventually, these motivated puzzle pieces just sizzle out in science, back into irrelevance, not unlike the endless preprints that rest uploaded on some digital archive. But just because it will sizzle out does not mean that scientific meme content is not so bad, or that it can not do a lot of harm in the short term.
Often, the real danger of scientific meme content comes from undue attention.
Case example 4: Bruttel et al. posting a preprint claiming to have identified ‘fingerprints for a synthetic origin’ of SARS-CoV-2, basically proving the lableak hypothesis. Now this extraordinary claim is in direct contradiction of multiple published papers that find that the SC2 genomes looks completely natural and is full of hallmarks of natural evolution and lacking any unnatural features. So what is going on? Did they find something everybody missed?
Well, let’s look at their methodology. Bruttel et al. look at restriction sites and their spacing throughout the SC2 genome and allege they have found one pattern that is hard to explain by mere ‘coincidence’ (How much ‘coincidence’ applies when we talk about evolution by natural selection is another topic, but okay…)
A little background:
Virologists (and other molecular biologists) use molecular cloning techniques to manipulate genomes, these range from introducing mutations to synthesizing whole genomes ‘de novo’, meaning without template just from the genetic information. Restriction enzymes are bacterial defense mechanisms against foreign genetic elements, DNA/RNA e.g from invaders like viruses. Restriction enzymes work basically as scissors that cut at specific sequence motif (often a short palindromic sequence) that they evolved not to have to avoid self-cutting. Scientists can use these molecular scissors to cut out (and glue back together with ligases) small streches of DNA and for a long time, these scissors were all they had (today, we have designer scissors) to create chimeric and designer constructs. Now for virology, where genomes can be rather sizeable, whole genomes can not be synthesized in one go, so one way to create them is to make a few large pieces, cut their edges with molecular scissors so they would have matching overlaps, and then glue the whole thing together like a long improvised sausage.
In the past, making these long genome sausages required some sequence compromises, because the recognition motifs where scissors could cut required specific nucleotides that had to be introduced (or removed for that matter to not get a false cut in the middle of your sausage). These are the ‘fingerprints’ of engineering Bruttel et al. claim to have found.
This brings us to the first criticism: The authors showed an incomplete understanding (i.e amateurish) of genome assembly methods, because although they suggested that the restriction sites of their choosing (BsaI and BsmB1) might have been used for Golden Gate assembly (a more modern method of genome assembly using restriction enzymes), Golden Gate assembly does not leave any footprints at all, they are lost during the cutting + gluing process.
But okay, soft criticism, after all, some genome assembly methods of the past did leave some restriction sites in (or made use of already exisiting ones and only removed ones that woud interfere with assembly).
There are many strong and substantial technical criticisms, including serious conceptual & methodological problems and shady practises (p-hacking) that I will just reference to, because I am already frustrated enough and don’t want to drag my readers through them all as well. (read summary here)
But what I really want to focus on is something more insidious about this preprint:
Anomaly hunting and a tactic called cherry-picking.
The problem with the whole concept of the preprint is that it makes strong, sensationalist claims based very shaky propositions; that the ‘spacing’ between restriction enzyme sites are that informative in the first place when it comes to genome assemblies. Given the hundreds of different molecular scissors, the endless amount of genetic diversity in viruses, no matter which natural virus is chosen, there will always be a set up restriction enzymes that have a ‘suspicious’ or anomolous spacing between them based on chance. Identifying such anomaly first (cherry-picking), and then doing comparisons of how unlikely it actually is given a set of assumptions, is prone to be misleading. (Incidentally, that is exactly what the authors did, even refusing to correct by multiple hypothesis testing)
But okay, let’s for a second assume the restriction enzyme pair they chose was not cherry-picked because it has an anomolous pattern that lends itself for the hypothesis, what else do the authors offer as evidence that this pattern could not have arisen naturally but only through ‘synthesis’ ?
And here, it gets really dark really fast.
One of their claims involve the supposed ‘mutation’ of conserved restriction side so that they would not interfere with the assembly. The idea is trivial: If likely progenitor viruses of SC2 all have a specific restriction side at the same position of their genome, but SARS-CoV-2 does not, it might indicate that the motif was ‘artificially removed’. This could be for example by just changing nucleotides in a way to remove the sequence motif (synonymous mutations), but not the amino acid coding. And behold, the authors claim that each position that ‘losts’ it’s restriction site had been just altered by a single nucleotide substitution. How suspicious is that, they ask, what are the odds this is a ‘coincidence’? Less than 1,2% they proclaim. (Very detailed but meaningless statistical claims are another trick to fool non-experts btw).
Now those of you who might recall basic biology lessions will know that the vast majority of all random mutations that persist in any genome are non-synonymous, because synonymous mutations change amino acid sequence and that comes either with a an adaptive benefit (in very rare cases), but most often, it causes a fitness detriment, thus most coding mutations are selected against. So it is perfectly expected that most changes to restriction side motives are single nucleotide synonymous mutations. But then you might ask:
How could the authors be so confident that there is only a 1,2% chance this is a ‘coincidence’? Well, they base their claim on a random mutations model (basically letting an algorithm change random nucleotides of the RaTG13 genome to see how often it would create a genome with as few restriction sites as SC2). This is of not an adequate model, given that it both ignores selection (mutations are not equally likely to retain) and ignores recombination (more on that in a second).
Treating all mutations and positions as equal just does not reflect biological reality, and this ‘ignorance’ of natural selection when convenient is of course a tactic “intelligent design” charlatans use to make their ‘statistical’ arguments of how unlikely so many ‘coincidences’ of life are. It’s stupid and should be laughed out of the room, and that is even before we remember that SC2 restriction sites were cherry-picked based on the fact that they were an anomaly.
But okay, I said it would get dark, so let’s continue.
For their hypothesis to make any sense, they have to show that existing restriction sites in other family members (ideally progenitors) are conserved, while SC2 uniquely lost them (i.e “the genome engineers took them out”), and the authors claimed to have done that by their statistical analysis showing only 1,2% odds that the lack of some specific sites is attributed to random mutation. Well, not so fast. How do we even know that other natural CoVs (ideally closely related to SC2) did not also lose the restricting sides ages ago? If a parent has a rare genetic mutation that occurs only once in a million genomes, the odds of offspring inheriting the same mutation are still 50%. Arguing that the offspring has only a 1:1000000 chance is ignoring conditional probability. Finding the same loss of restriction sites in the CoV family tree could be quite informative indeed.
Well, I guess you know where I am going. Of course, there are such SC2 relatives (shown below, RpYN06, a closely related SC2-like bat virus from Yunnan region), the authors just did not include them in their comparison. This is of course surprising, given that RpYN06 would constitute unequivocal proof that SC2 restriction sites were not engineered.
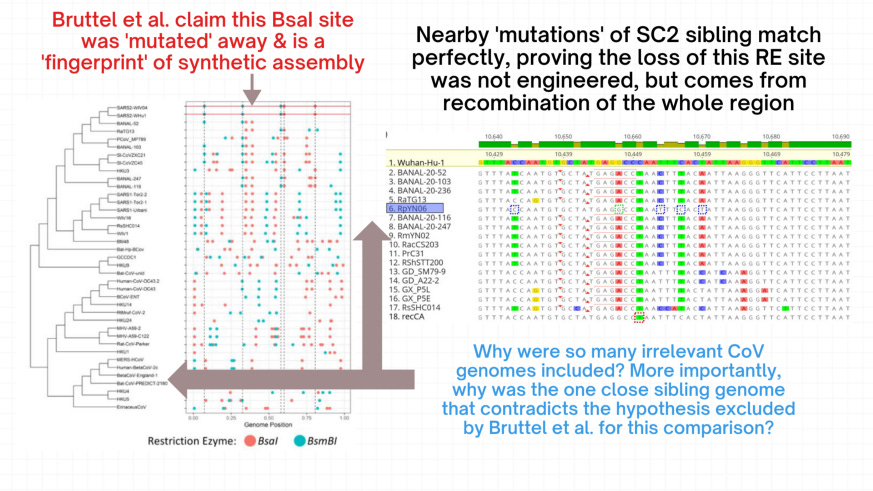
The above figure clearly is quite a beautiful proof that most of the anomaly-hunting bullshit bingo Bruttel et al. cooked up is perfectly explained by viral recombination (the mechanism that drives most CoV diversity and is responsible for the ~27-piece mosaic genome of SC2).
However, it also speaks volumes about Bruttel et al., who either accidentally or purposefully excluded the one genome (of a relevant SC2 relative with high similarity!) from the analysis that would contradict their whole hypothesis.
The former would be gross incompetence, the latter misconduct or fraud.
Given the number of irrelevant genomes they decided to include to boost their claims, and the subsequent low likelihood of missing out on the ones that matter, I certainly know what to bet my money on. Incompetence is also hard to sustain as an explanation given that the authors were explicitly informed by experts about the RpYN06 genome months ago, and how it contradicts their conclusion.
Given this history, there is little wiggle room to argue for “accidental” exclusion. I think it is justified to assume that this was intentional and fraudulent conduct by the authors (more supporting evidence for this assumption is also in Chapter 2).
So what do I want readers to take away from this? The reddest of all red flags:
Lemma IV: Scientific misrepresentations, cherry-picking, or committing fraud
And while this might be a red flag only experts can really identify with confidence, we would do well to take it to heart and try to understand it. If multiple experts explain exactly how and why something amounts to such gross scientific misconduct, the public ought not to be forgiving. (Worth mentioning that scientific misconduct is not considered a crime, outside of scientific institution, it has no repercussions, that’s why some actors do not shy away from it.)
Of course, for most papers, scientific misrepresentations and cherry-picking, and fraud are things that the peer review process often filters before it ever reaches a wider audience. Preprints certainly warrant extra critical reflection from amplifiers who choose to engage and cover a preprint version of any scientific study.
Amplify first, back peddle later has unfortunately become a business model for many influencers and journalists in the fast-paced attention economy
Yet when the media and society pay undue attention to preprints, they usually do not suffer the repercussions. It’s the scientists who are put in a tough spot. And we have to talk about it.
Section C) The asymmetry of debunking bad science
One inherent problem of any made-up bullshit is that it usually takes ten times more work to explain why it is wrong than it takes bullshiters to produce it. (This phenomenon is sometimes called Brandolini’s law, or bullshit asymmetry principle)

Why is it so much work? In order to refute, one has to first educate non-experts about a whole array of technical things non-experts are unaware of, starting from vocabulary to basic science to relevant domain knowledge to logical fallacies and statistics. All unpaid, of course.
We have to understand that this has been the state of things for years now for some virologists, and don’t get me started on climate scientists and other domain experts who happen to work on a topic engulfed in public controversy. It is irresponsible for society to demand scientists debunk any and all sensationalist claims that motivated actors, amateurs, and conspiracy theorists come up with. Sometimes, we should just heed the advice of some experts:

But of course, being very plain and dismissive about it (rather than doing the labor-intensive point-by-point technical refutation nobody will read) is just more reasons that scientists get attacked on social media as ‘not offering substantive critique’, ‘elitist cabal dismissive of other ideas’, ‘afraid to engage with alternative views’ etc.., including from supposed journalists who should know better than stealing all our time with false equivalency garbage.
The irony is of course that this behavior is forcing extra unpaid work on virologists and exposes them to harassment and character assassination at the same time no matter what they do. Debunk, and the motivated actors will harass you for speaking up. Don’t debunk, and the lies about you, your profession, and your work will poison the info sphere. Wonderful situation, right? Maybe society ought to do better on this one?
Maybe journalists, influencers, and platforms have to learn that in the attention economy, this platforming of ‘both sides’ in the name of ‘neutral reporting’ or ‘balance’ is putting science at a disadvantage, helps cranks spread their bullshit, and poisons the info sphere.

Scientists are all sick and tired of the restless attempts from influencers, journalists, and politicians (and others) to make any scientific topic a controversy or second-by-second cage fight between contrarian cranks and mainstream scientists.
And if I am to wager a guess, I’d say wider society is sick and tired of it too.
Summary chapter 1
One problem with our broken info sphere is that it has no memory and no time for validation. Because attention constantly wanders to the newest shiniest thing, people forget to ask about the basics. Are the people advancing sensationalist claims that go against mainstream science actually credible? What is their scientific track record in the domain area? Have they made false claims before? Do they profit from sowing doubt, advancing a narrative, or gaining attention?
It would be good for journalists, influencers, and other amplifiers to understand that amateurs make rudimentary mistakes when it comes to nuanced scientific topics. Just because a person might have a PhD in an unrelated field and uses technical language does not mean they are qualified to contribute to the topic. In fact, one has to be very skeptical when these epistemic trespassers advance sensationalist hypotheses that are in stark contradiction with much of the field. We would do good to remember that extraordinary claims demand extraordinary evidence, but even better if we did not expose ourselves to wrong claims constantly.
So unless contrarian ‘experts’ advance data and evidence-based claims in the peer-reviewed literature that other scientists deem credible points of discussion, it is probably wise to not amplify them in the media. In fact, the sheer act of covering contrarian scientists, even critically, might play into their hands and creates a false equivalency.
Platforming amateurs advancing contrarian scientific opinions in the attention economy is not neutral coverage, it’s taking their side over science.
An even bigger problem is that motivated, dubiously financed or shady actors have no moral quarrels misrepresenting, cherry-picking results, or even committing scientific fraud in service of their conspiracy myth. Nor do the people who profit from keeping the myth alive.
There is currently no punishment for committing scientific fraud outside of institutions. Science is reputation-based, institutions have power of scientists, but influencers and fraudsters act mostly outside the structures of science, creating scientifically-looking meme content directly for public consumption and personal gain, not a scientific audience.
Even worse, much of that meme content is used to attack the reputation and credibility of domain experts who speak up for truth and the public good.
The disconnect between science and society is a vulnerability that will be increasingly exploited with the power shifts the attention economy and asymmetric information architecture brings with it.
Given these circumstances, scientists are lost without the public.
So what can we do?
Chapter 2: Trusted voices, disqualifying traits, and anti-science information operations
Everybody can learn to spot (some) scientific meme content
Section A) Information literacy and credibility as a network power
If you are like most people, you will have skipped (or at best glanced) over the scientific technobabble and debunking in Chapter 1. Most people do not have the time, skill, or passion to go into the weeds on every single controversy, nor should they. Time and attention are valuable goods in the information age.
But one does not need to be a domain expert to spot some ‘universal’ red flags in scientific meme content, often with remarkably little time investment, if one knows what to look for.
Let’s revisit our example 4: Bruttel et al., claiming they have found ‘fingerprints for a synthetic origin’ of SARS-CoV-2 based on some cherry-picked irrelevant anomaly of restriction enzyme cutting sites, flawed statistics, and likely fraud. Now how does one go about assessing the strength of such claims when one does not even know what restriction enzymes are? Instead of googling restriction enzymes, how about we do a quick Twitter search for the first author (Dr. Bruttel) on the preprint and some keywords like ‘natural origin’, ‘man-made’, or similar?
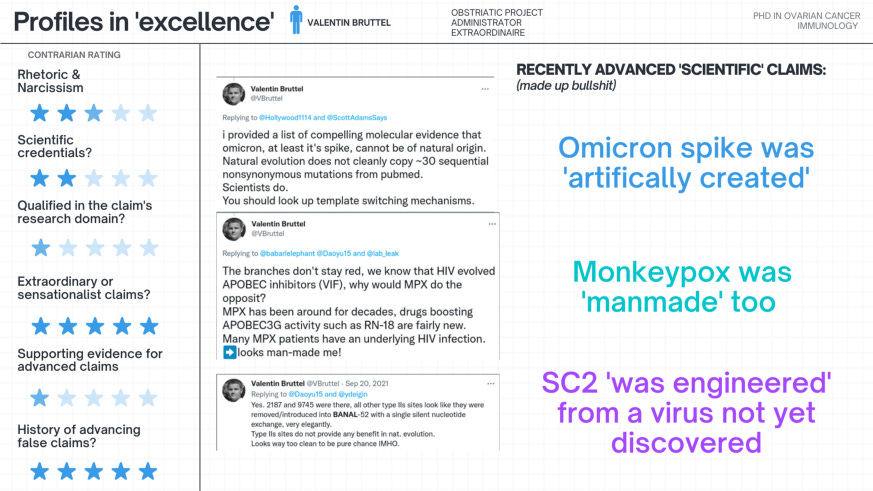
It really does not take much longer than googling, but instead of finding out about the variety of endonuclease motifs, we would find a very different kind of pattern: One of a person who has made unsubstantiated and radical claims before about various different viruses. This brings me to a very obvious red flag:
Lemma V: Credentialed ‘experts’ holding wrong or anti-scientific stances on other topics are not trustworthy on any scientific topic
Now just to be clear: I do not think everybody has to do this.
Even a five-minute Twitter search is five minutes wasted on bullshit.
Doing this kind of basic due diligence, fact-checking, and getting second opinions is supposed to be the bread and butter of journalists before they spread such preprints. Failure to do so is journalistic malfeasance.
But in the attention economy, influencers perform a very similar role to journalists; they spread information, with the important difference that they are not bound by any journalistic standards or editorial/institutional practices. An influencer just presses the retweet (in the case of Twitter) button and measures success based on engagements.
Too many influencers, especially contrarian ‘scientists’ and those who pretend to be, fall for scientific meme content
I see no good reason why influencers should be allowed to continue to do that, but that is a different discussion. If a scientist spreads scientific meme content, it should have professional repercussions. But the fact remains that for the majority of amplifiers, there are currently no mechanisms in place to hold them accountable.
All I ask from my readers is that they do not share sensationalist claims from amplifiers, ever, before doing the basic due diligence these influencers unethically outsource to their followers.
In an ideal world, democratic citizens should not follow influencers that have such low amplification standards, and the best way to not be manipulated online is indeed by having a curated set of people to follow that have higher standards to spreading information.
And this brings me to credibility as a network power:
From the beginning, only two groups of people (networks) seem to have had a good handle on the lableak topic. First are the domain experts, virologists, epidemiologists, and other people familiar with the ubiquity, danger, and science of emerging zoonotic diseases and the technical skill to assess the evidence. Duh.
More surprisingly is the second group, a mixture of journalists, anthropologists, psychologists, medical doctors, climate scientists, and disinformation researchers, basically people who have professional experience with anti-science tactics and/or conspiracy myths.
The latter is familiar with the patterns of argumentation such a conspiratorial worldview brings forth, on top of other critical hallmarks of conspiratorial ideation; i.e the fact that it never stops at one conspiracy theory.
Not everybody who believes in lableak is a conspiracy theorist, but every conspiracy theorist believes in a lableak.
People (and influencers!) who believe Ivermectin is a suppressed wonderdrug against Covid often also believe vaccines do more harm than good, climate change is not a real problem, and a whole array of other absurd things about AIDS, ‘big pharma’, 9/11, (((globalists))) and so forth, with all their coded language and dog whistles and faked doubt about science and strategic ‘just asking questions’ spiel. It is boring and predictable, but in this case, understanding this ‘alternative network’ feature can also be helpful to discern credible arguments from scientific meme content.
When people heavily engaged in alternative reality ecosystems advance false or misleading claims, or belief in absurd nonsense on a whole range of topics, it is also a very pertinent red flag:
Lemma VI: Repeated amplification of false and misleading content on a range of topics
Even when one has no passion or patience in assessing specific lableak claims, the sheer fact that most of the lableak proponents are climate change contrarians, or anti-vaccine or AIDS origin conspiracists should give any reality-associated individual some pause on the validity and merit of the whole endeavor, or at least most of these claims. (Worth mentioning: Serious voices investigating all possible origin scenarios are legitimate and welcome, all the anti-science, political and conspiracy myth noise around the topic is actally making their life much harder)
The obvious problem with outsourcing our trust completely to network features and proxies is of course our reliance on having cultivated a good information network in the first place. And that might be a problem when motivated actors do everything in their power to create alternative networks where up is down and black is white.
Section B) The weaponization of scientific meme content
In this article, we covered a lot of scientific meme content, what the public might not know is that the crew around Massey, Quay, Deigin, Bruttel, Rahalkar, Washburne (and many, many others!) are of course not first-time offenders. They have a history of pushing scientific meme content that they use for media attention, most of which are blogs or preprints following the same scheme of misrepresentation, cherry-picks, and misconduct to advance the conspiracy myth or throw dirt at the work of domain experts.
What the public might also not be aware of:
They get amplified because there is a market for attacking science which goes beyond audience attention
To understand it, let’s first look at a final, short case example: The conduct of Dr. Washburne, a computational biologists, and p-hacker extraordinaire who has made many dramatic, sensationalist, and conspiratorial claims. He also has been creating advanced meme content using flashy (but widely considered irrelevant or misleading) statistics and figures for a whole range of topics surrounding Covid, including most recently the Bruttel et al. ‘synthetic origin’ preprint and another harshly refuted meme preprint targeted at Pekar et al. (Dr. Washburne was also apparently instrumental in pushing the sensational ‘synthetic origins’ preprint to lableak-friendly journalists, unfortunately successfully, culminating in a widely decried and irresponsible clickbait article from the Economist)
I do not have the insight nor interest to detangle how much of Washburne’s actions are driven by narcissism, conspiracism, and delusions of grandeur (these traits also correlate) versus personal profits and network incentives. There is clearly something not right when a washed-out postdoc in microbiology claims to be a finance genius, or that he turned his back on a billion-dollar patent, or that independent scientists like himself get silenced by research cartels that manufacture consent (and on and on it goes), all without any shred of evidence.

All I know is that it would be unethical of me not to mention that he has been featured by the Brownstone institute (a propaganda outlet financed by rightwing billionaires) to push the Great Barrington declaration (which Dr. Washburne also created scientific meme content for).
The Great Barrington Declaration was a ‘public health’ *cough* proposal to not do anything against the spread of SARS-CoV-2, a misinformed, stupid, and anti-scientific idea that somehow *wink wink* found its way into public discourse and policy (Zenone M. et al., PLOS Global Public Health, 2022).
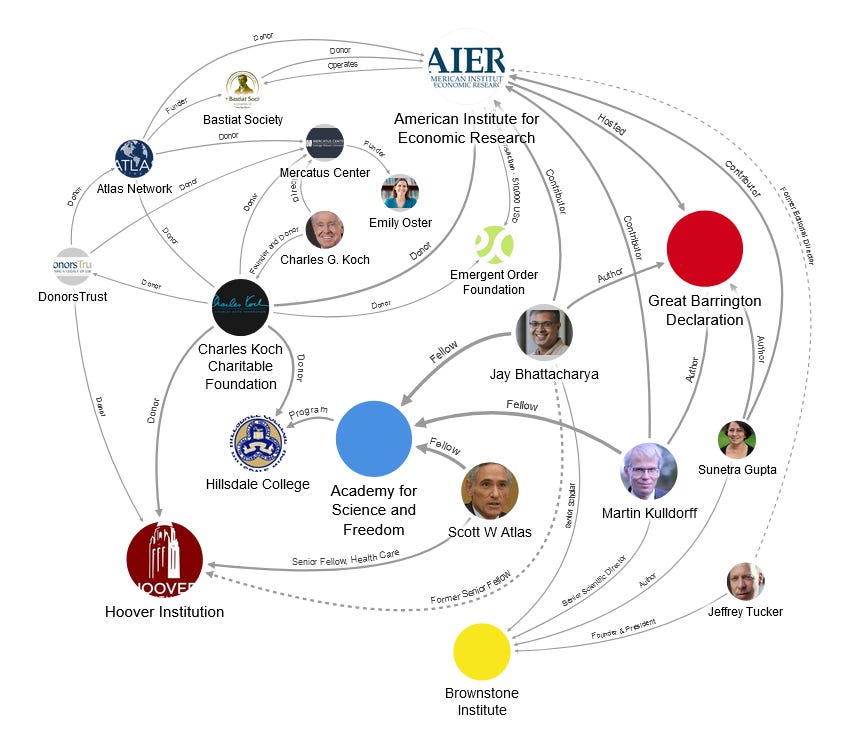
Furthermore, Dr. Washburne has written other meme ‘preprints’ claiming the pandemic is has reached ‘natural endpoints’ because of herd immunity in the summer of 2021 (in service of rightwing states, with his ‘analysis’ showing that not doing lockdowns performed best), and in general creates content that rightwing anti-science actors use to attack scientists and scientific consensus, including Fauci and vaccines (here is Dr. Washburne leading an event with notorious anti-vaccine extremists Robert Malone, Steve Kirsch and fellow GDB influencer Kulldorf (paid by Brownstone institute).
Now let me be clear: There is no evidence that Dr. Washburne directly receives any money, and my personal belief is that he does not, just a grand narcissist that found himself a willing and useful participant in this ideological network and its inauthentic amplification tactics. Please consider that this is my opinion and that is obviously clouded by my interactions with him and his work. So always consider consulting others and not take my assessment as final word on it.
Just to round this section out, I should mention that Dr. Washburne is also currently advocating (and fund-raising) to create an alternative ecosystem for science as well. If you read between the marketing and lofty buzzwords of his vision, he draws a picture of mainstream science and scientific processes as fundamentally corrupt.
A research cartel — a set of researchers aligned in their beliefs and often sharing funding, publications, conference talk opportunities, and more — can gain a monopoly over a field by fully securing crucial battlegrounds with their team. If a research cartel monopolizes editorial positions at the top peer-reviewed journals, they can simply delay and reject competitors’ work as “not impactful” without ever having to peer review. […]
By centering scientists as royalty-earning content-producers, we believe it’s possible to re-wire the entire scientific ecosystem in a way that improves the value of science and the pay of scientists. — Alex Washburne, CEO of Salva
Dr. Washburne seems to long for a world where scientists become content creators (much like himself), even to be compensated for the ‘science’ they produce. You know, like those ‘scientists’ who work for the tobacco and oil industry. Now I do not know about you, but in aggregate, the behavior displayed by Dr. Washburne certainly sounds like a red flag to me.
Lemma VII: Smearing domain experts with decades of respectable research work with claims of catastrophic bias, trivial errors, or ‘hidden’ conflicts of interest when publishing in their field
Now before we move on to the final section, there is something else I have to talk about as a responsible blogger:
A word on naming individuals
While this article is not about the individual actors, the format of explaining bad science and tactics inevitably highlighted the names of some individuals, just by the fact that their name is on the preprints chosen. I want everybody to understand that directed frustration at them is unnecessary, they are mostly interchangeable.
If not for them today, it would be other faces tomorrow doing the same thing.
But just naming individuals comes with the potential of online harassment, and this is explicitly not what I intend for any of these actors (in the unlikely event this article goes viral, I have to emphasize this: I do not condone any harassment, dog pile, or crowd-sourced witch hunts against individuals, even unethical ones, ever! Witch hunt justice is no justice, just more unethical self-gratification)
My recommendation (for our sanity) is that we collectively just ignore, block, and mute these actors instead of engaging with them. My real recommendation is that we change the information systems that are so vulnerable to them.
And this brings me to the last important question: Who exactly profits from scientific meme content creators acting this way?
Section C) The method behind the madness
As many of you might be aware, there is no shortage of animosity against scientists found online. The uncertainty of the pandemic brought a variety of scientists to the forefront of society; virologists, epidemiologists, vaccine researchers, and doctors were in demand and many did the best they could to explain, advise and help society navigate the pandemic.
This newfound power and authority of science of societal decision-making did not go down well with more traditional power-holders, from influencers to businesses to politicians.
While we were talking about information as a product when it comes to crowd-sourced distortions by influencers and individuals, disinformation researchers and cyber specialists in the military talk about information as a tool of war when conceptualizing the role, impact, and purpose of targeted manipulations.
What both conceptional approaches have in common is that the content of the information is irrelevant, only the effect matters. Facts, accuracy, context, reliability, and other desirable traits of information are often even counterproductive when it comes to optimizing information products or tools. For information as a product, consumer engagement determines its value. For information as a tool, information space strategic utility determines its value. Scientific meme content have high strategic utility in the various information operations of anti-science information combatants.
Information operations are inauthentic actions of a coordinated group, from the state level and businesses down to disinformation contractors, pay-to-engage services, chat rooms, and message boards; they may include fake identities, content, messaging, or amplification; and they pursue a social, economic, or political purpose.
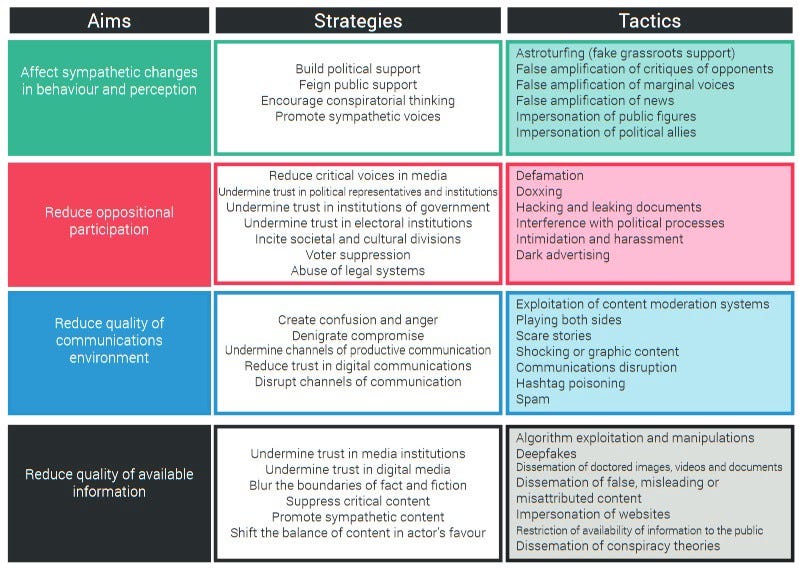
People might be more familiar with ‘information operations’ directed against science than they think.
Ever since the tobacco industry’s manipulation of public health science on cigarettes (just read about the tactics against scientists coming from the tobacco industry), scientists and the public should recognize that manipulating scientific information and attacking domain experts is a tactic for motivated actors to further their strategic aims.
The truly remarkable part about all of this is how mundane and old these tactics are.

Businesses, individuals or other information combatants using disinformation playbook tactics against scientific experts to harass them out of public conversation is as old but still very effective, especially in times of social media where there is a crisis of trust in experts. But let me reiterate:
Smearing domain experts with decades of respectable research work with claims of catastrophic bias, trivial errors, or ‘hidden’ conflicts of interest when publishing in their field is a big red flag.
Given all the meme content examples we have seen today, I believe the ‘information operation’ framework is important to understand for wider society.
Scientific meme content is a threat to society.
As I said in the beginning, this was an article collecting examples from the lableak controversy, but it might have very well been an article about many other scientific topics, vaccines, climate change, and Ivermectin, to just name a few. The specifics might differ, but the larger patterns hold the same.
We all can learn to spot some of the patterns and tactics of anti-science actors, and one does not have to be a domain expert to do that. We have to understand that some meme content producers are elevated, amplified, or even directly paid by anti-science networks to do just that: Attack mainstream science and sell doubt. And if the last few years have shown anything, it’s working like a charm.
It does not help us to be naive about it.
We as a society have to admit that we are currently lacking the information literacy to spot these info-warfare tactics
Furthermore, in the information age, society needs to develop a resistance against manipulation by sensationalist claims, especially ones that go against the scientific consensus.
This is the small part we all can do, and throughout the article, we collected some nuggets of insight on where to start.
Conclusion
We started this article with a simple question: Where does the discrepancy between science and society come from?
The sad answer is that there are many reasons and few fixes.
In today’s world, we do not have the attention span to judge each new claim on its merits, first because we lack time, will, or expertise to assess the merit, and second, because advancing lies and baseless claims is a lot easier than correcting them.
Sometimes known as Brandolini’s law, this bullshit asymmetry robs us of our time and senses, every day we get flooded with so much garbage about ‘how mainstream science is wrong about this or that’, so we cognitively concede, believing that ‘maybe there is reason to doubt’ the scientists or scientific consensus, why else would there be so much noise?
People familiar with dirty politics understand of course what is going on, motivated actors are abusing scientific meme content to throw shit at the wall of science in hopes that something will stick, well-knowing that any cleaning-up effort by scientists takes an order of magnitude more work than it takes motivated liars to just make up ever new shit to throw. Even worse, the shit-throwers and liars get all the sensationalist attention in our broken info sphere, whereas the cleaning up and technical corrections often go unnoticed in the attention economy.
There is of course a method behind this madness.
We have to understand that scientific meme content is not just an unfortunate side effect of a broken info sphere, it has strategic utility for motivated actors, and has to be evaluated in this context.
It does not matter that the actors creating meme content have no scientific credibility in the domain, or usually don’t get their (amateur or fraudulent) content published in the first place. What matters is that meme content can be publicly thrown at scientists to gain attention and sow doubt, to elevate the thrower and his alternative narrative, and bring the scientists into a conundrum of either putting in the arduous amount of (unpaid!) work to refute (that most people will not even see), or having lies about them and their work stand (which will often lead to harassment).
Social media enabled everybody to throw dirt towards a scientific consensus they don’t like, and many agitated followers of toxic influencers go towards harassing, doxing, and even threatening scientists who dare speak up to correct the record.
Scientifically-looking meme content (authentically produced or not) plays a crucial role in information operations against science. The reason why climate scientists and disinformation researchers have been so attentive to the mechanisms of the lableak conspiracy myth is that they have been fighting the same anti-science fight for decades.
A fight that is getting harder given that the deck is stacked against scientists in the currently broken information sphere in pretty much every way possible. So in a sense, this article is also a plea for help.
Scientists are powerless to fight asymmetrically empowered anti-scientific forces without the public
One thing individuals can do is to increase their own media and science literacy, if not for scientists, so at least for themselves so they don’t get easily manipulated.
Throughout this article, we have collected a set of lemmata, small nuggets of insights that can help readers identify ‘red flags’ for bad science:
Lemma I: Amateurs make amateur mistakes
Lemma II: Sensationalist claims based on flawed or trivial analyses
Lemma III: Unqualified authors, reviewers, and unethical or unscientific conduct
Lemma IV: Scientific misrepresentations, cherry-picking, or committing fraud
Lemma V: Credentialed ‘experts’ holding wrong or anti-scientific stances on other topics are not trustworthy on any scientific topic
Lemma VI: Repeated amplification of false and misleading content on a range of topics
Lemma VII: Smearing domain experts with claims of catastrophic bias, trivial errors, or ‘hidden’ conflicts of interest when they have decades of respectable work publishing in their field

Now while this might not be a perfect or complete list to filter out all disinformation peddlers or catch every self-serving influencer or contrarian eccentric pushing misleading meme content online, it certainly might help us individuals to make an ex negativo call for assessing scientific credibility.
Maybe it is naive, but it is a start to reclaim power from the manipulators and bring science and society closer together again.
There are no perfect solutions for trust, but I believe scientists and citizens alike profit when we can reduce uncertainty and noise in our quest to approximate ever more likely truths.
And that is worth fighting for.
References:
Jiang & Wang, Science, 2022 (Perspective)
Worobey M. et al., Science, 2022
Pekar J. et al., Science, 2022
Yuan S. et al., Journal of Interactive Advertising, 2020
Dal-Ré R. et al., Research Ethics, 2020
Brand AM., Am J Public Health. 2012
Zenone M. et al., PLOS Global Public Health, 2022
Further reading and resources:
Blog: The case for a zoonotic origin of SARS-CoV-2
Blog: Lableak myth influencers & their fear-based communication tactics
Blog: How algorithmic curation empowers controversies
Blog: How our information architecture favors conspiracy myths over science
Video: Long-form discussion with SAGO member Dr. Carlos Morel (SAGO is the WHO’s scientific advisory group on the origins of pandemics)
Video: Long-form discussion with bat ecologist Dr. Alice C. Hughes and the risk of SARS-CoV-3
Video: Long-form discussion about lab leak uncertainties with virologist Dr. Stuart Neil
I will be writing more about asymmetric power in the information age. If you are interested in featuring my upcoming articles or working with me on a related project, please reach out.
This article took time and effort to conceptualize, research, and produce, but I do not want it locked behind any type of paywall.
I see this work as a public good that I send out into the void of the internet in hopes others will get inspired to act.
So feel free to use, share or build on top of this work, I just ask you to properly attribute (Creative Commons CC-BY-NC 4.0).
Quote/Cite this work:
Markolin P., “Scientific meme content”, substack, October 25, 2022
This was a phenomenal job of writing and makes me wish we could get all of our journalists to step up and start looking for and telling the truth. I'm inspired! Thank you!
"(‘lableak’) theory is dead in the water"
Clearly, you have difficulty understanding probability. You also have very poor understanding of human behavior. If there was no leak, why this massive cover up?
Even Geraldo Rivera figured out the probability.
Root cause of COVID-19? Biotechnology's dirty secret: Contamination. Bioinformatics evidence demonstrates that SARS-CoV-2 was created in a laboratory, unlikely to be a bioweapon but most likely a result of sloppy experiments
https://doi.org/10.5281/zenodo.3766462
Last nail in the coffin of wet market cock and bull stories.
https://www.biorxiv.org/content/10.1101/2022.10.18.512756v1